When the population mean \((\mu)\) is known, then the population variance (\(\sigma^2\), 母分散) is
\[
\sigma^2 = \frac{1}{n}\sum_{i=1}^n\left(x_i - \mu\right)^2
\] However, we usually do not know the population mean. So, we must calculate the sample variance (標本分散).
Sample variance and the unbiased sample variance)
There are two ways to calculate the sample variance.
Sample variance (標本分散)
\[
\widehat{\sigma}^2=\frac{1}{n}\sum_{i=1}^n\left(x_i - \overline{x}\right)^2
\] The value of the sample variance \((\widehat{\sigma}^2)\) is smaller than the population variance (母分散). In otherwords, if \(n\) is small, then \(\widehat{\sigma}^2 \ll \sigma^2\).
Unbiased sample variance (不偏標本分散)
\[
s^2=\frac{1}{n-1}\sum_{i=1}^n\left(x_i - \overline{x}\right)^2
\] When \(n\) is small, use the unbiased sample variance (不偏標本分散 \((s^2)\)).
Unbiased sample variance (不偏標本分散)
x = {4, 6, 2, 9, 3}
mean: 4.8
deviation: x = {-0.8, 1.2, -2.8, 4.2, -1.8}
n: 5
z = x -mean(x)n =length(z)sum(z^2) / (n -1) # 数式で求めた値
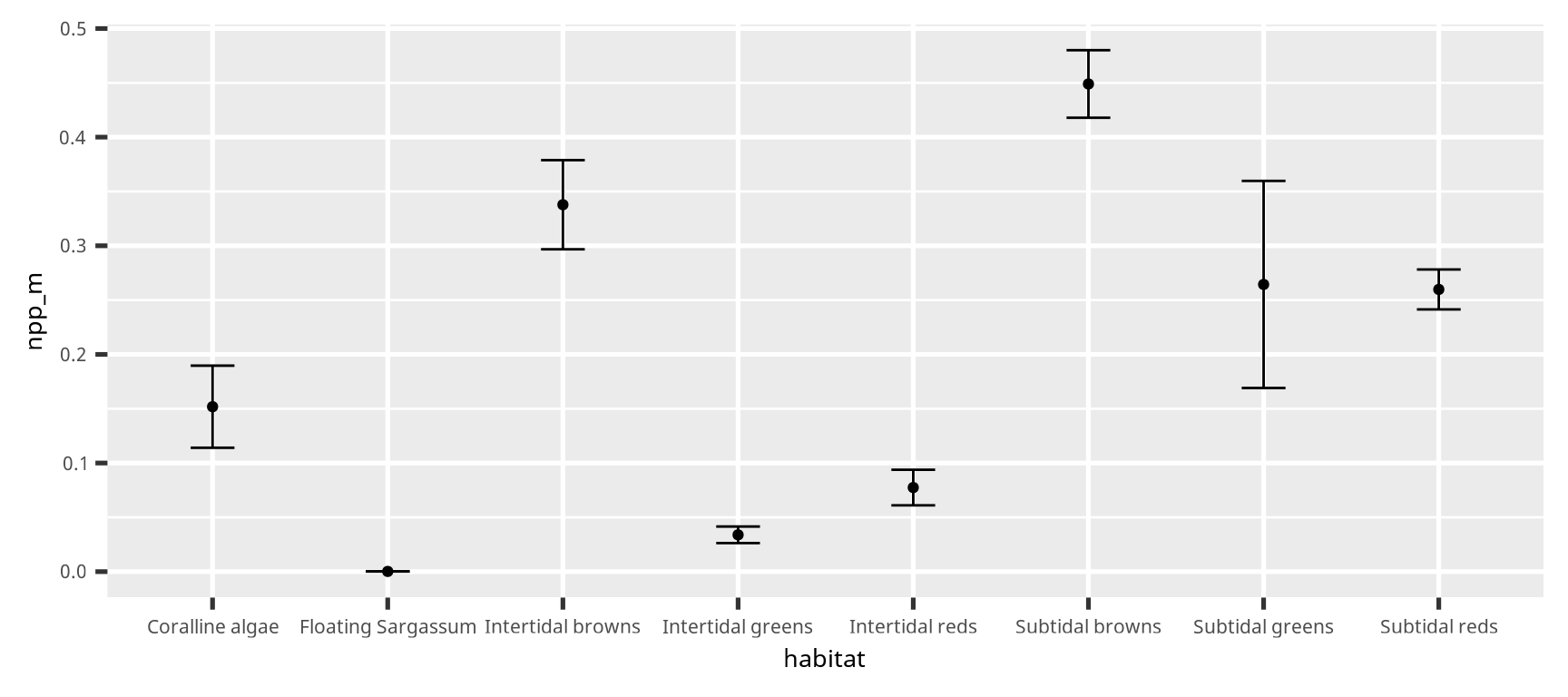
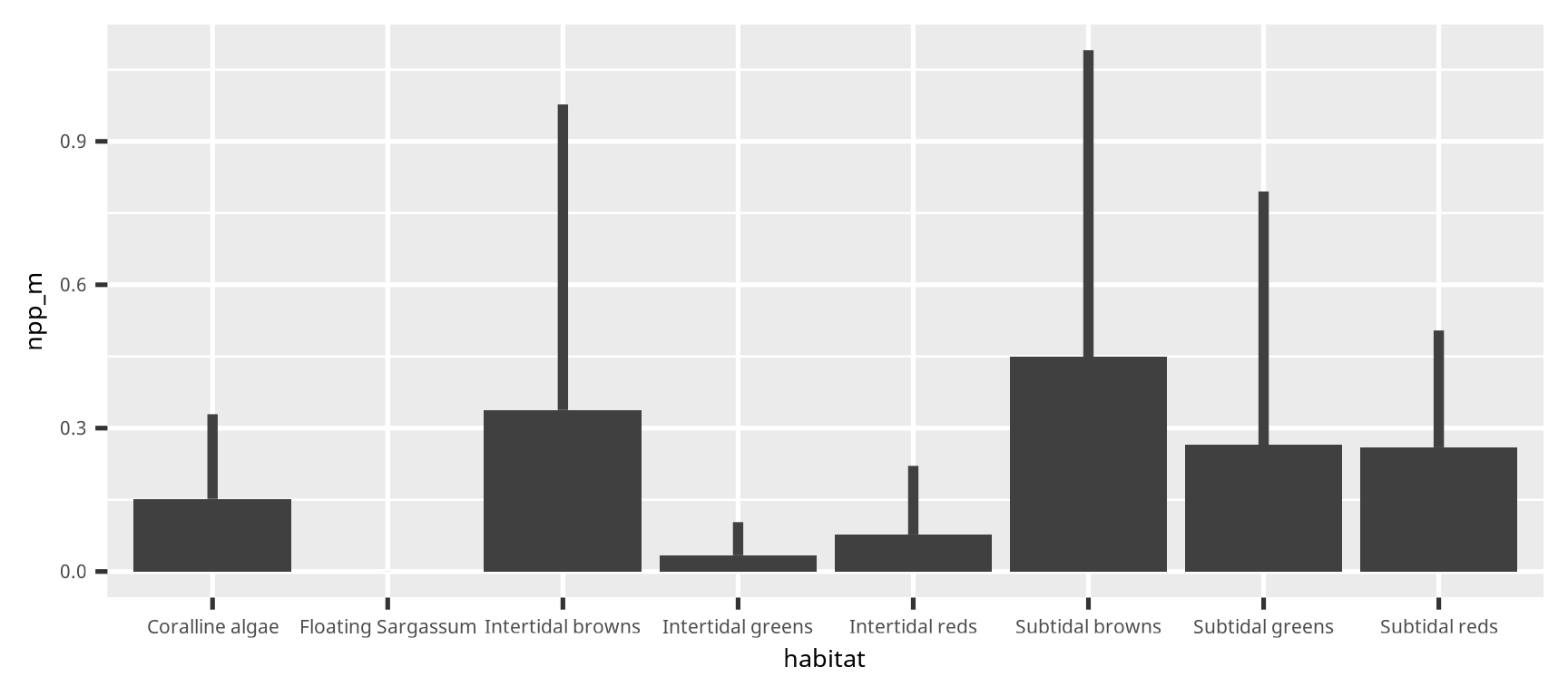
Variance (分散) describes how much the data is scattered around the expectation (mean). Since the sample variance is \(\sim\sum(x - \overline{x})^2\), it cannot be directly compared with the mean.
The standard deviation is the positive root of the variance. Both variance and standard deviation describe the scatter of the data. Which variance to use? \(\widehat{\sigma}^2\) or \(s^2\)
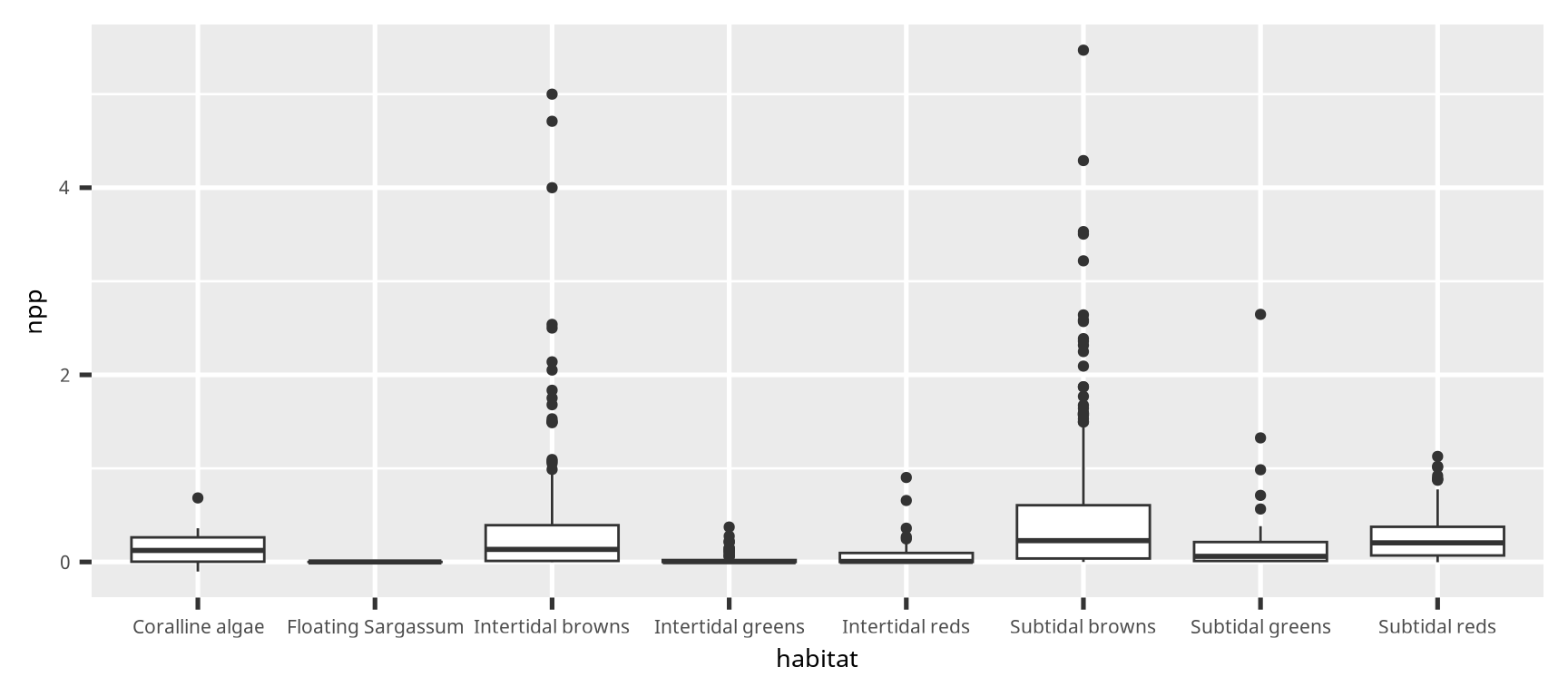
The median (中央値・メディアン) is another statistic to describe data. It is the midpoint of data that is sorted from small to large values. When the number of data is odd, the median is the value at the midpoint. When the number of data is even, the median is the average of the two values nearest to the middle.
There are many ways to define the quantile (四分位数・クォンタイル). In any case, we first need to sort the values from smallest to largest. Then we separate the values in to four groups. The value used to separate the groups are called the quantile.
In this boxplot, the whiskers indicate the minimum and maximum values. The line in the center of the box is the median (i.e., second quantile, 第2四分位数). The bottom edge of the box is the first quantile (第1四分位数) and the top edge of the box is the third quantile (第3四分位数). The distance between the first and third quantile is called the Inter-Quantile Range (IQR, 四分位範囲).
Quantile in R
set.seed(2021)z =rpois(100, 10) quantile(z)
0% 25% 50% 75% 100%
3 7 9 12 25
In the standard boxplot, the dots beyond the whiskers indicate outliers. The whiskers extend to the largest value within 1.5 times the IQR from the each edge.
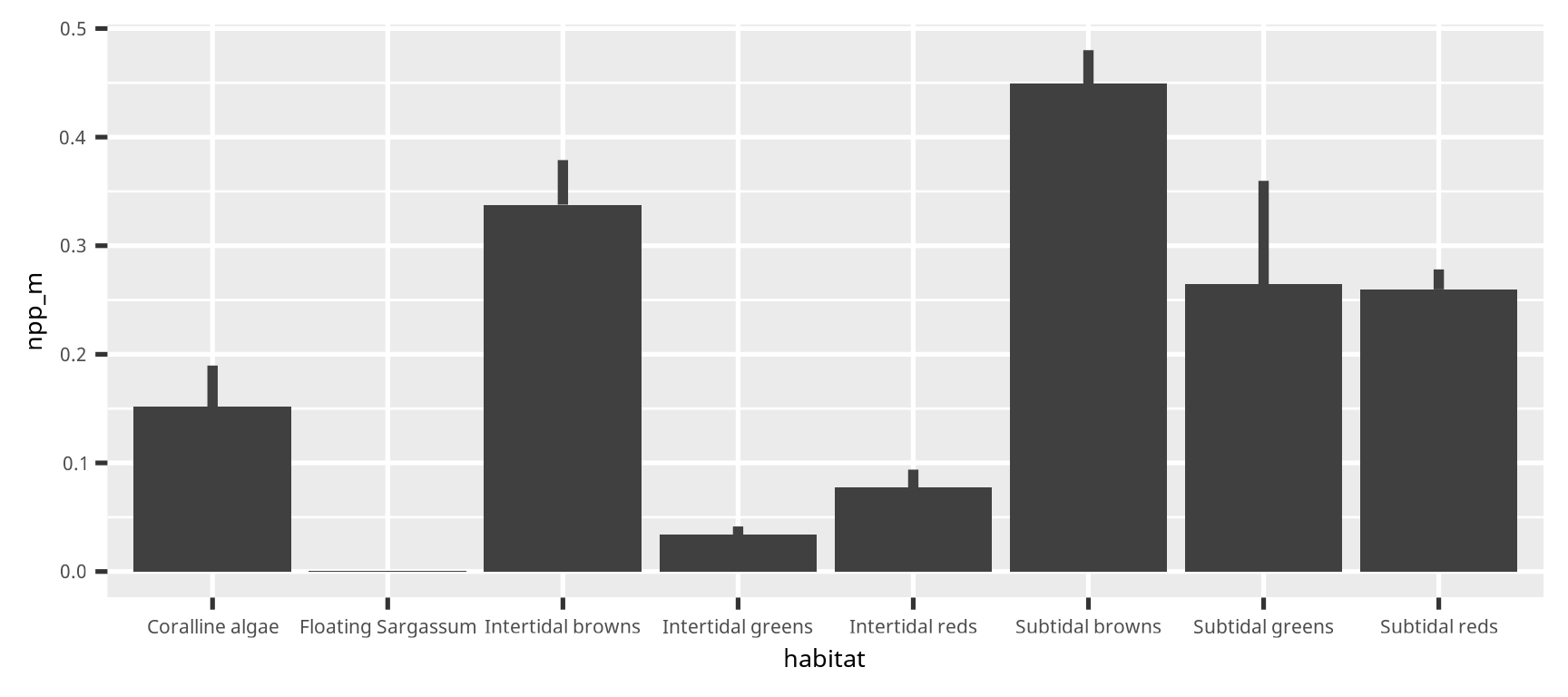
データの可視化
Data
Duarte et al. 2022. Global estimates of the extent and production of macroalgal forests. Global Ecology and Biogeography 31 (7): 1422 - 1439. https://doi.org/10.1111/geb.13515
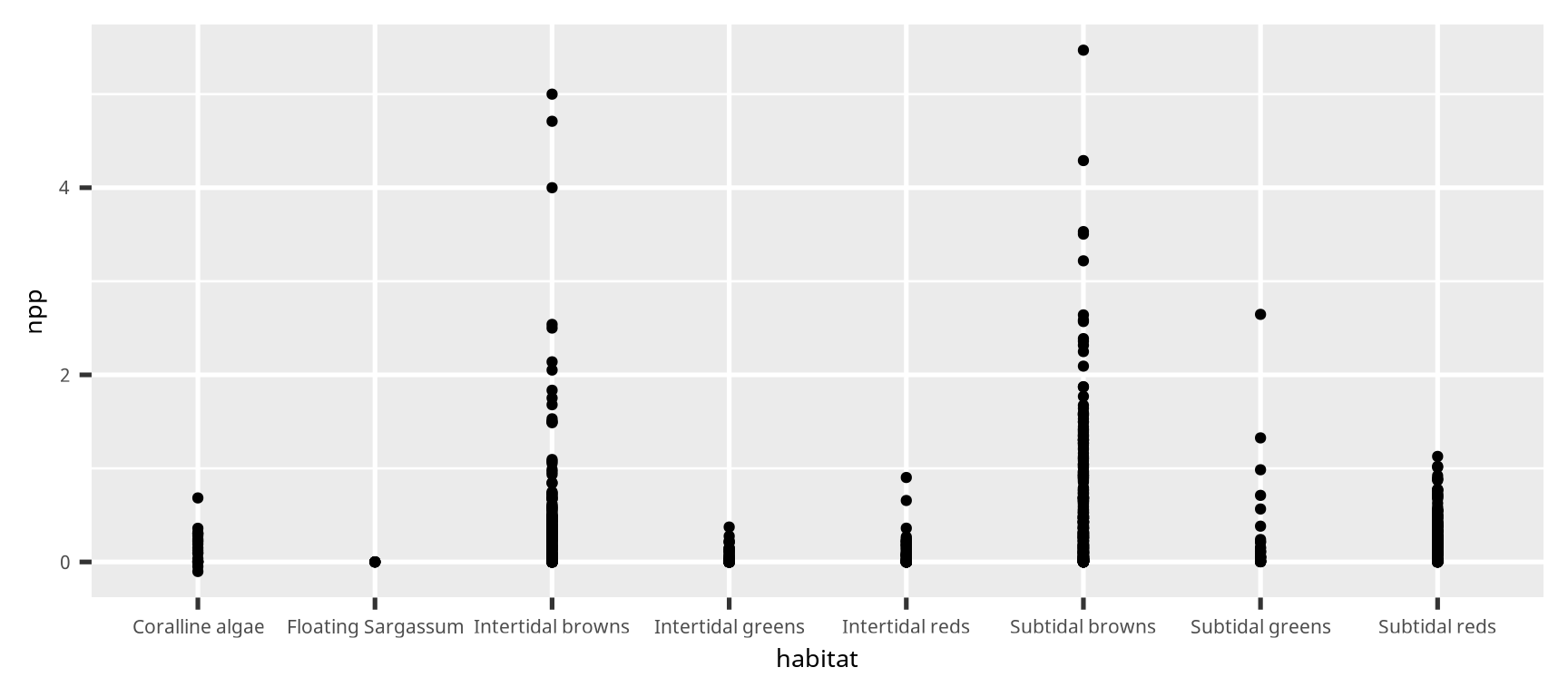
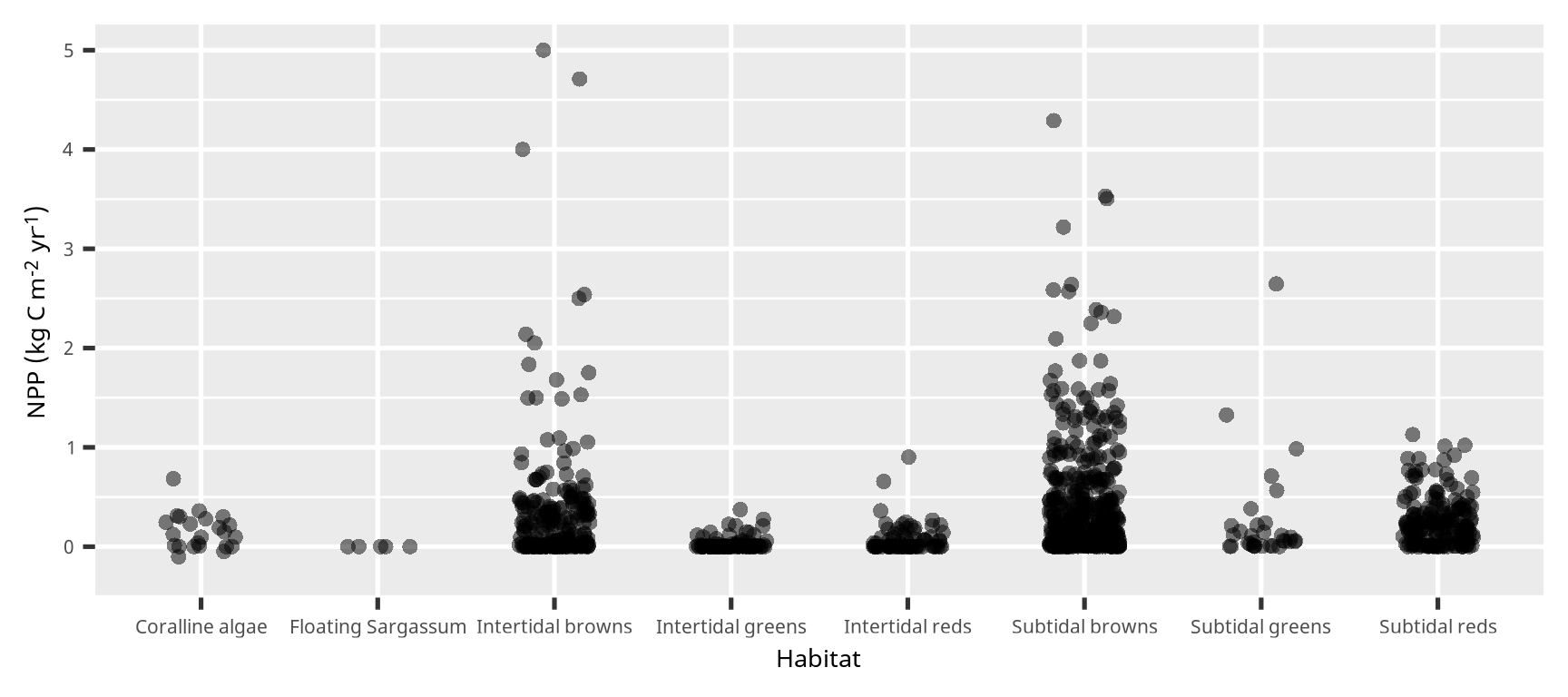
散布図 (scatter plot)
ggplot(dset) +geom_point(aes(x = habitat, y = npp))
散布図 (scatter plot)
横軸は因子 (factor)、または離散変数 (discrete variable)
散布図とジッター (scatter plot with jitter)
ggplot(dset) +geom_point(aes(x = habitat, y = npp),position =position_jitter(0.2))