大数の法則と
中心極限定理
中心極限定理
2024 / 07 / 07
度数 (frequency)
度数(頻度)とは
ある標本で特定のデータの値が得られた回数。 相対度数は標本数に対する度数の割合です。
{3, 1, 5, 1, 4, 2, 5, 2, 3, 2, 6, 3, 3, 1, 3, 4, 1, 4, 4, 2, 1, 6, 1, 1, 1, 2, 1, 2, 6, 4} に対する 6 の度数は 3 です。
相対度数は

です。
コイン投げの例
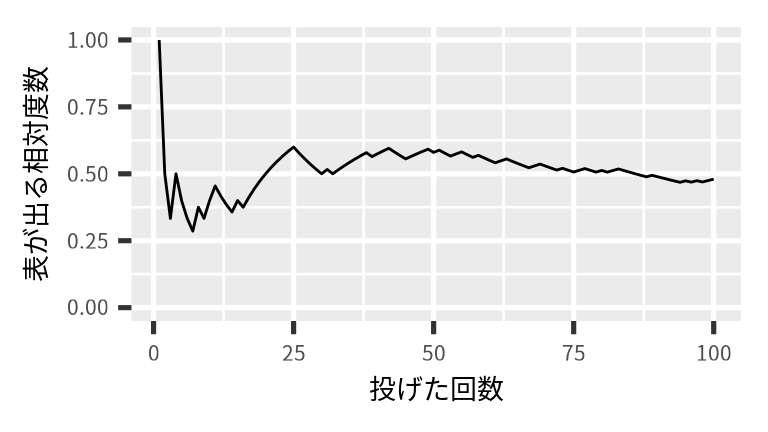
フェア (fair) なコインを投げた場合、表が出る確率は 0.50 です。 では、コインを 100 回投げた場合、 表がでる相対度数は 0.50 でしょうか。
コイン投げの例
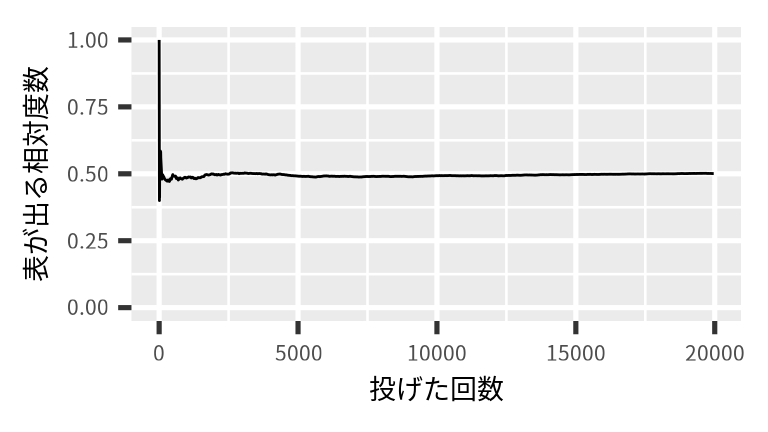
今回の実験では、 表が出る度数が 0.50 に収束するためには、 おおよそ 15,000 回投げました。
コイン投げの回数が少なければ(小数) 表が出る確率と相対度数に大きな違いがありましたが、 投げる回数が増えると(大数)相対度数と確率の違いは小さくなりました。
平均値のデモ
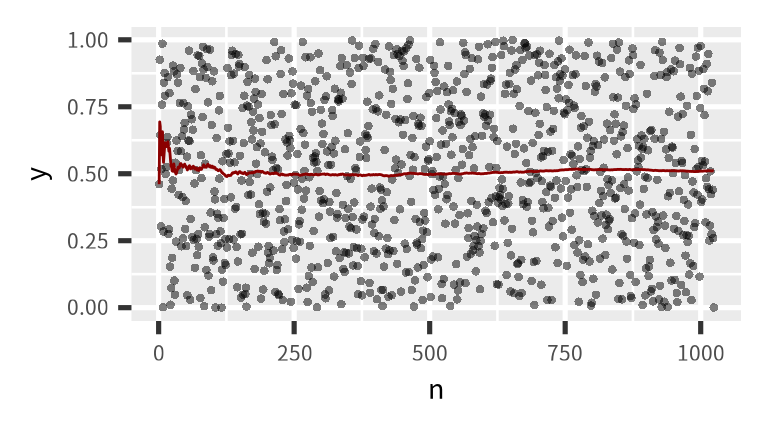
標本 (y) は 0 から 1 の一様分布に従う確率変数です。 点は y の観測値、線は y の累積平均値(標本平均)です。 標本数が増えれるにつれて、y の標本平均(線)は母平均 (μ = 0.50) に収束する。
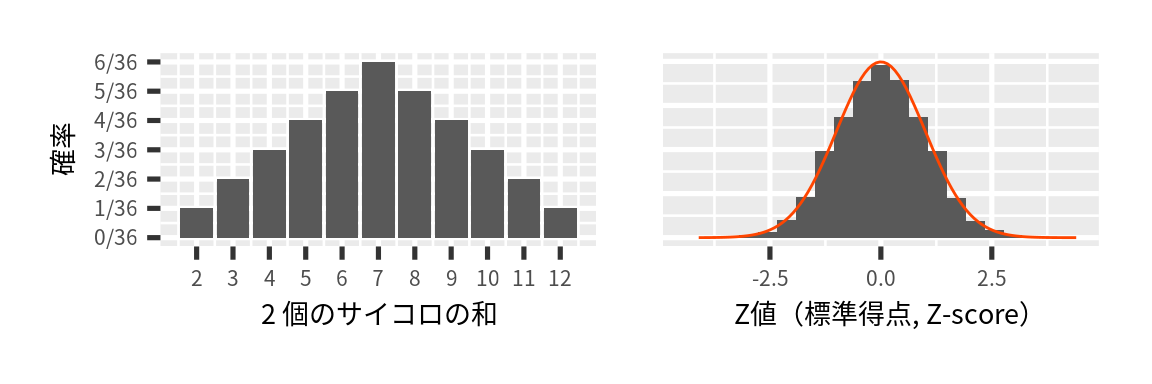
一回の実験に2個のサイコロを49回投げました。 実験は 215 回繰り返して行い、実験ごとに2個のサイコロの和の平均値を求めました。 標準平均から母平均(7)を引いたあと、標本の標準偏差で割りました \((Z = \frac{x_i - \overline{x}}{s})\)。 もとのデータの分布は正規分布ではないが、平均値は正規分布に従っています。
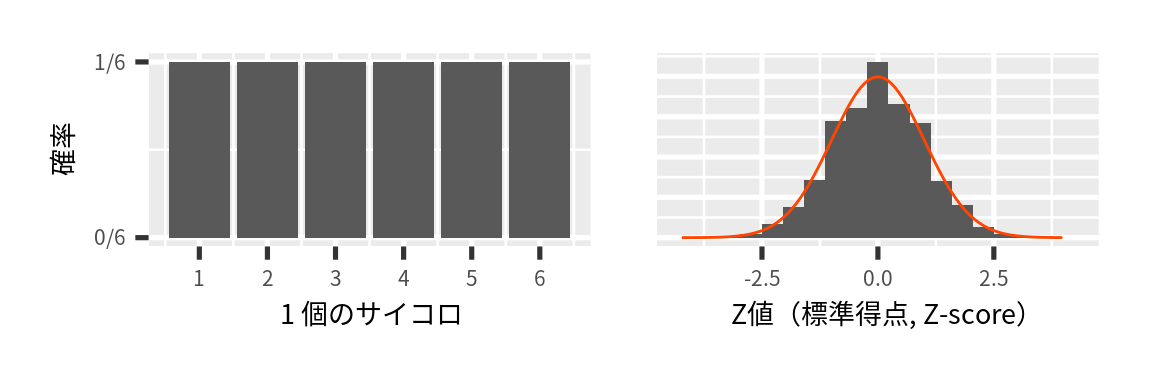
一回の実験に 1 個のサイコロを49回投げました。 実験は 215 回繰り返して行い、 実験ごとに 1 個のサイコロの出目の平均値を求めました。 標準平均から母平均(3.5)を引いたあと、標本の標準偏差で割りました \((Z = \frac{x_i - \overline{x}}{s})\)。 もとのデータの分布は正規分布ではないが、平均値は正規分布に従っています。
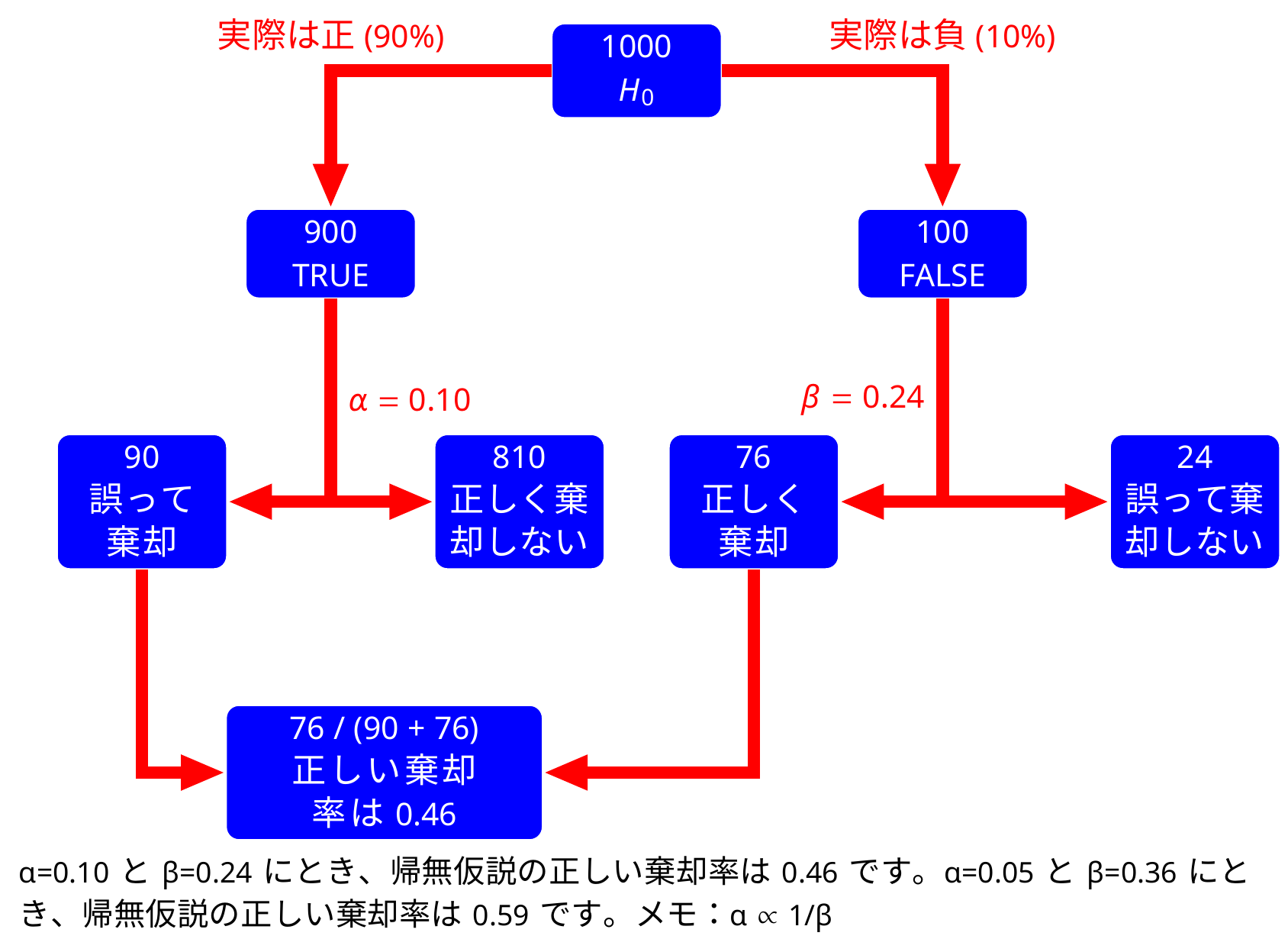
帰無仮説は正しいときのP値
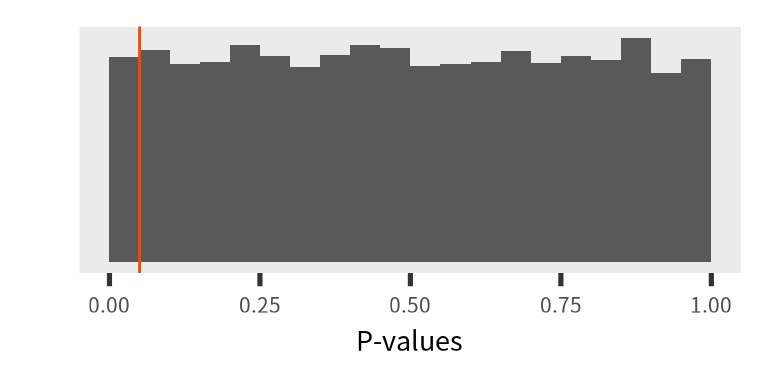
帰無仮説が正しいとき \(((\mu_0=50) = (\mu_A=50))\)、 P値は一様分布に従います。 実験を10万回繰り返し実施たとき、 \(P(\text{P-value}<0.05) = 0.0501\)でした。
帰無仮説は正しくないときのP値
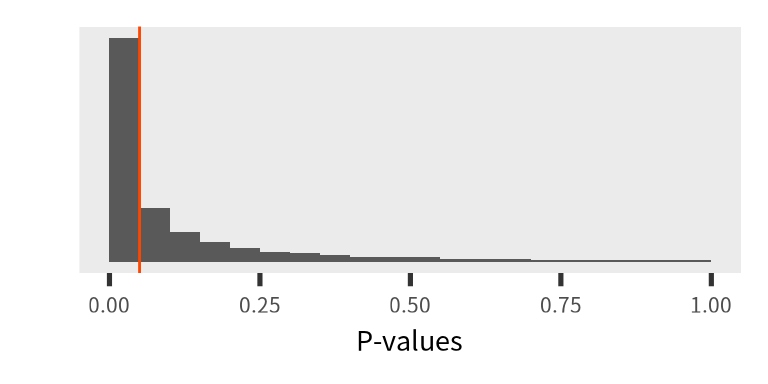
帰無仮説は正しくないとき \(((\mu_0=50) \ne (\mu_A=51))\)、 P値は一様分布に従いません。 実験を10万回繰り返し実施たとき、 \(P(\text{P-value}<0.05) = 0.5604\)でした。
第1種と第2種の誤り
Amerhein et al. 2019. Nature 567: 305-307
Let’s be clear about what must stop: we should never conclude there is ‘no difference’ or ‘no association’ just because a P-value is larger than a threshold such as 0.05 … –Amerhein et al. 2019
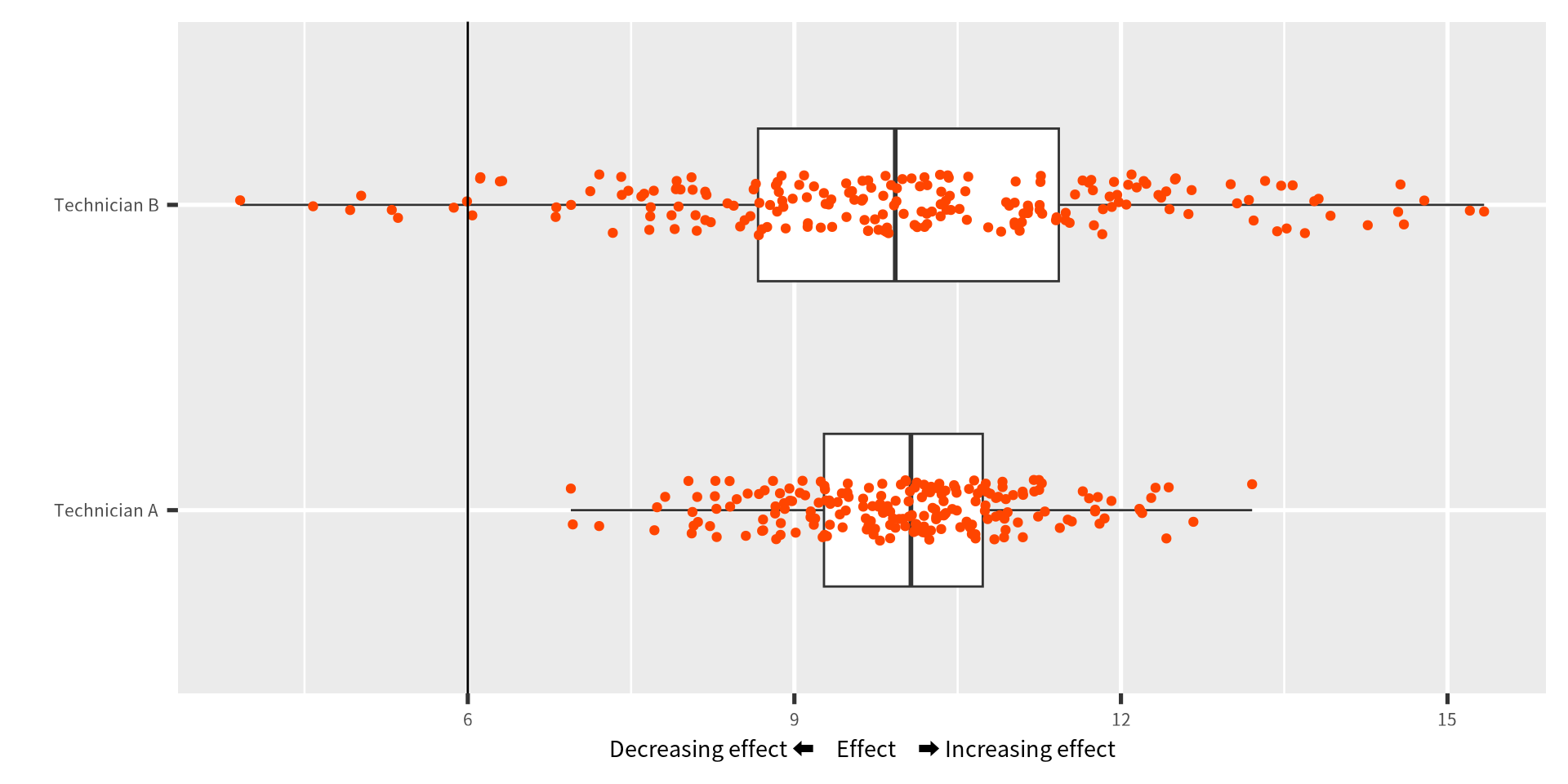
P値は 0.05 より大きい場合、「違いはない」、「実験の影響はない」、 「関係性はない」のような解釈は誤りです。
\(P>0.05\) は、帰無仮説を棄却するほどの情報量がないだけを意味します。 決定的に実験の効果がないまでは言えませんが、効果がなかったことについては丁寧に考察する必要はあるでしょう。 帰無仮説を棄却したときも同じように疑いながら結果の考察は重要です。 たまたま棄却できたときもあります(第2種誤り)。