Principal component analysis (PCA) is a method to find new variables (i.e., principal components) that are linear functions of the original variables. The new variable should successively maximizes variance and should not be correlated with each other. The principal components are found by eigenanalysis (Jolliffe and Cadima 2016; Hotelling 1933; Pearson 1901).
Principal component analysis (PCA)
PCA1 is the eigenanalysis2 of the \(p\times p\) variance – covariance matrix3\(\Sigma\)
where, \(\mathbf{V}_{pca} = \begin{bmatrix}\mathbf{v_1} & \mathbf{v_2} & \cdots & \mathbf{v_p}\end{bmatrix}\) is a matrix of \(p\) eigenvectors1 and \(\mathbf{L}\) is a diagonal matrix of the eigenvalues2. Each \(\mathbf{v_i}\) is also known as the \(i\)th principal component3.
Eigenvalue
The eigenvalue matrix is a \(p\times p\) diagonal matrix1.
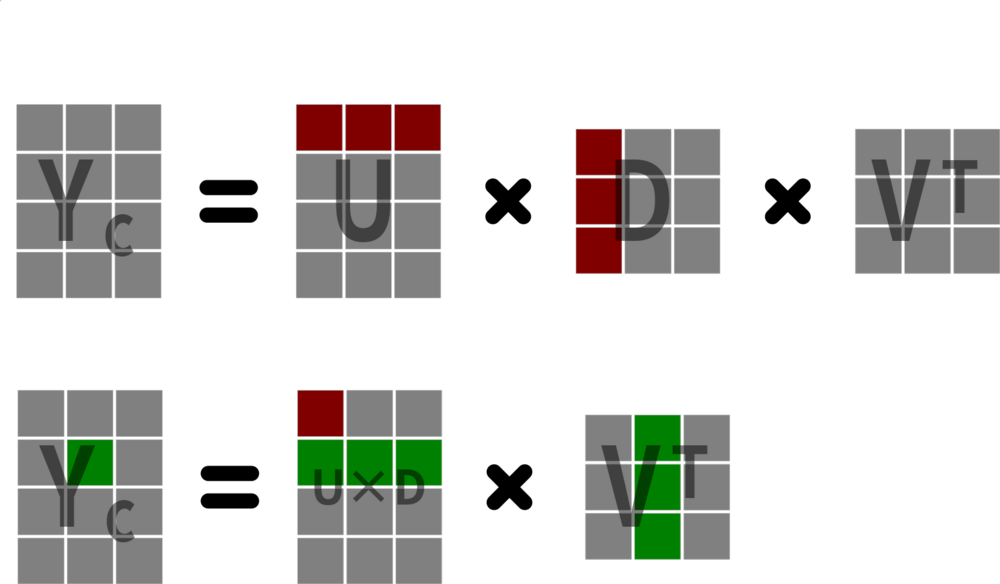
Instead of solving \(\frac{\mathbf{Y_c}^\top \mathbf{Y_c}}{n-1} = \mathbf{\Sigma} = \mathbf{V}_{pca}\mathbf{L}\mathbf{V}_{pca}^\top\) (i.e., eigenanalysis1), it is easier to do a singular value decomposition (SVD)2.
or more simply, \(\lambda_i = \frac{d_i^2}{n-1}\).
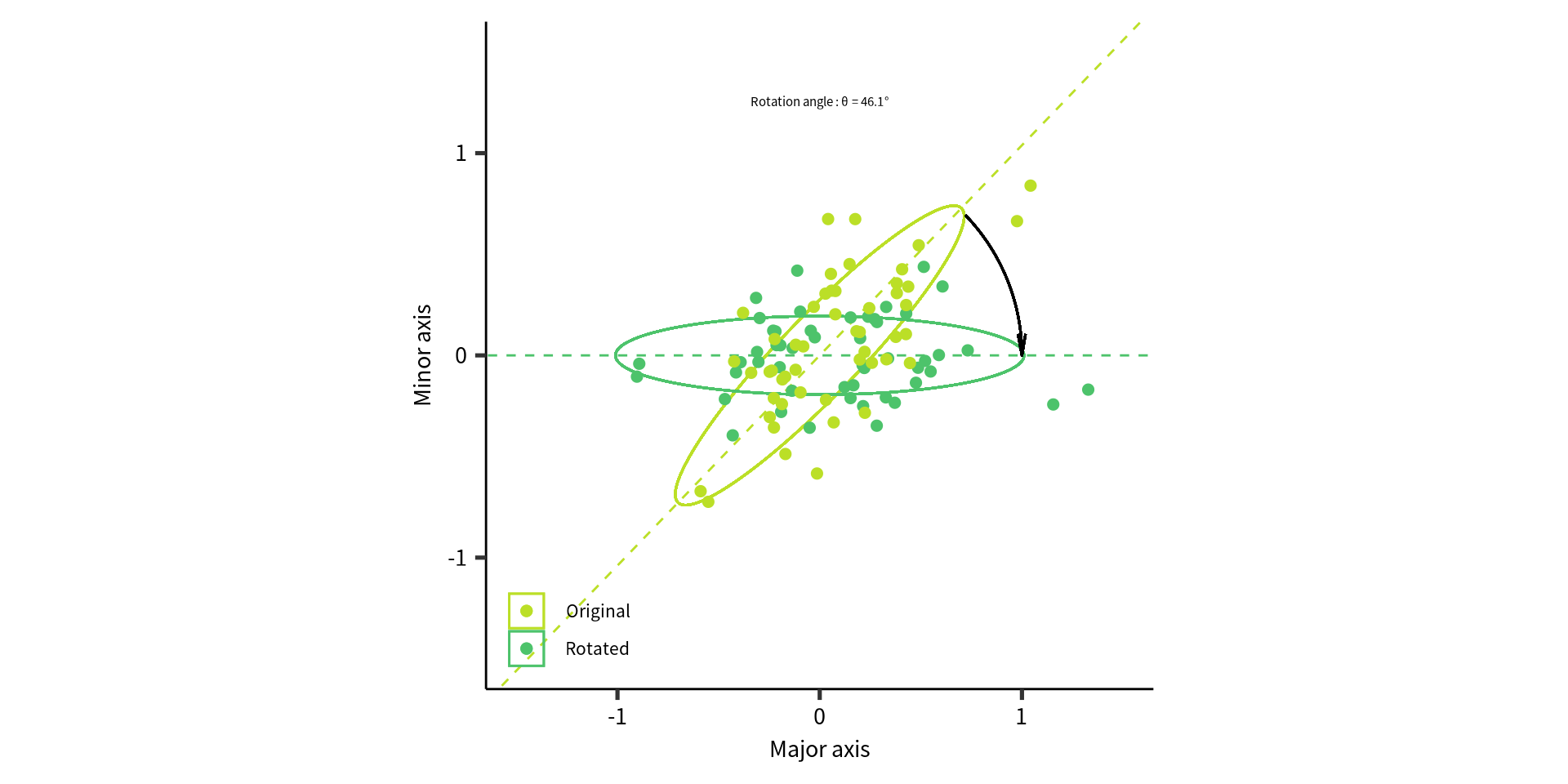
Visualize what we want to do
The rotation angle \(\theta\) can also be determined from the rotation vector as follows: \(\mathbf{V}_\text{svd} = \begin{bmatrix} \cos\theta & -\sin\theta\\ \sin\theta & \cos\theta\\ \end{bmatrix}\).
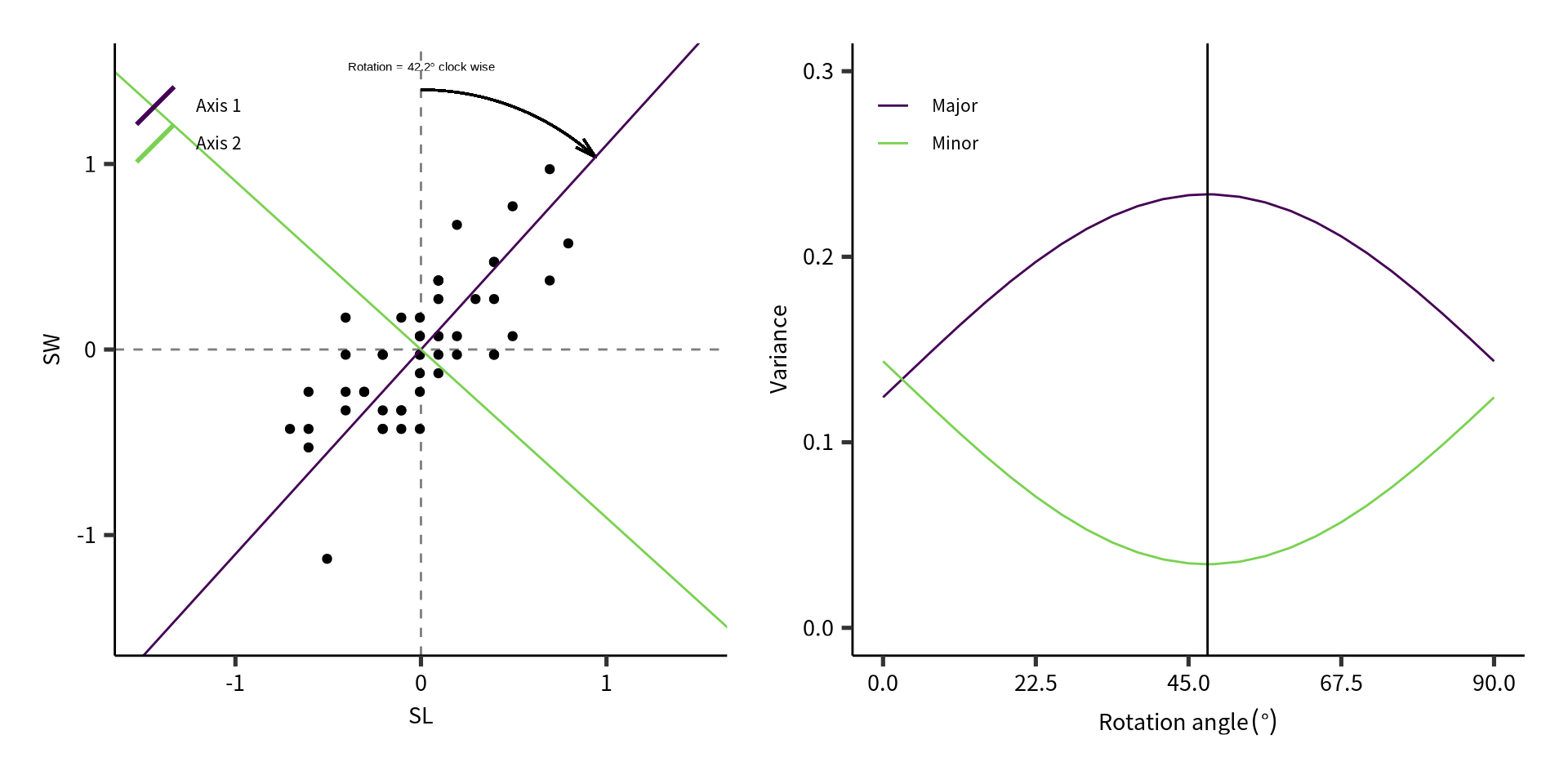
Computation mechanics
Apply SVD to the previous example results in the following equation.
Therefore, for variable SL, the loadings on PC1 and PC2 are -0.325 and -0.137, respectively. The cosine of the angle between loadings are their correlation.
Call:
rda(X = Yc)
Partitioning of variance:
Inertia Proportion
Total 0.2679 1
Unconstrained 0.2679 1
Eigenvalues, and their contribution to the variance
Importance of components:
PC1 PC2
Eigenvalue 0.2337 0.03428
Proportion Explained 0.8721 0.12793
Cumulative Proportion 0.8721 1.00000
Scaling 2 for species and site scores
* Species are scaled proportional to eigenvalues
* Sites are unscaled: weighted dispersion equal on all dimensions
* General scaling constant of scores:
Note the total inertia is the sum of the eigenvalues 0.268.
The proportion explained is the ratio of the eigenvalues to the sum of the eigenvalues \((\lambda_i / \sum{\lambda_i})\).
Example 2: vegan-like analysis
In vegan::rda(), the scores are scaled according to the following:
\(\mathbf{U}_1\) and \(\mathbf{U}_2\) are the scaled scores.
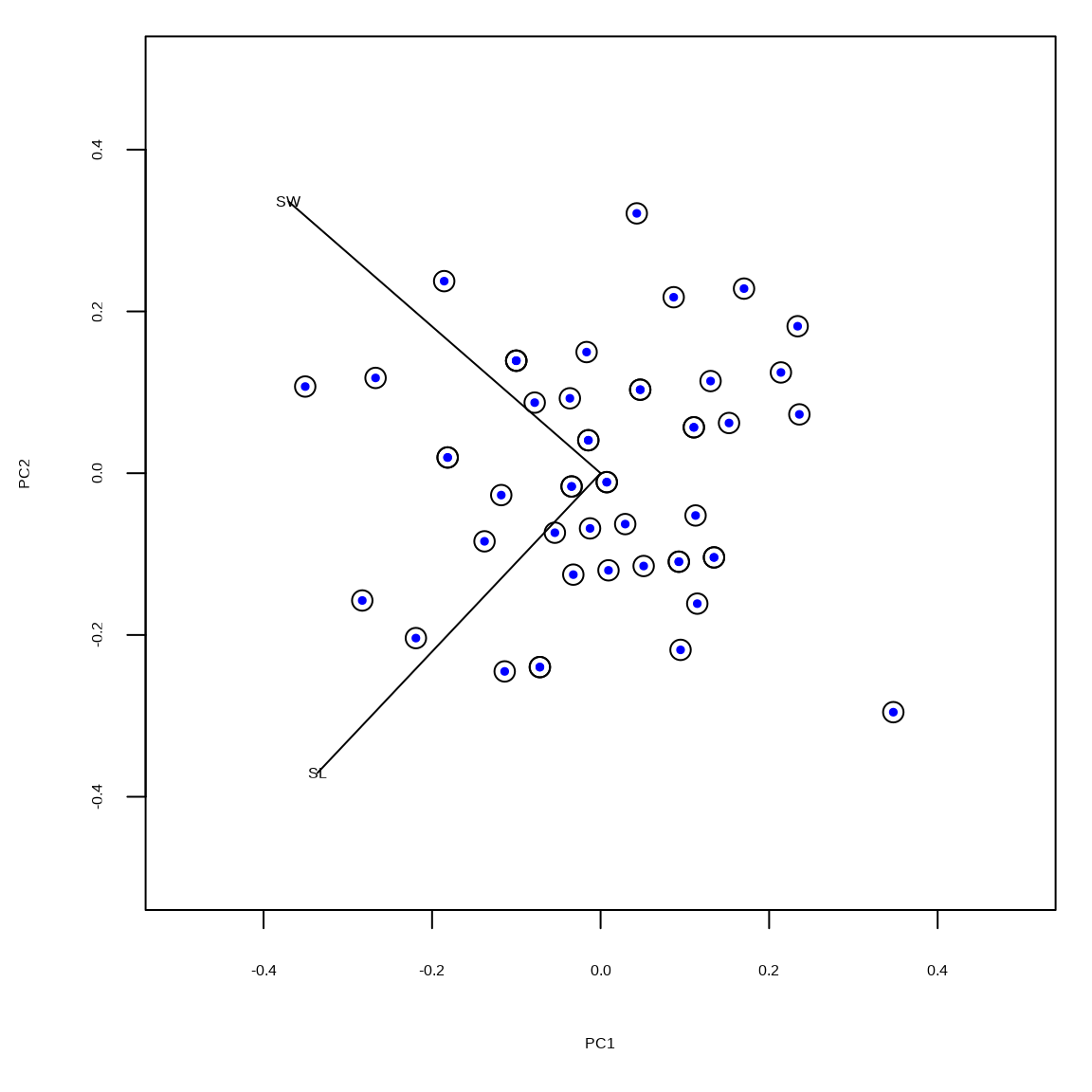
Example 2: no scaling
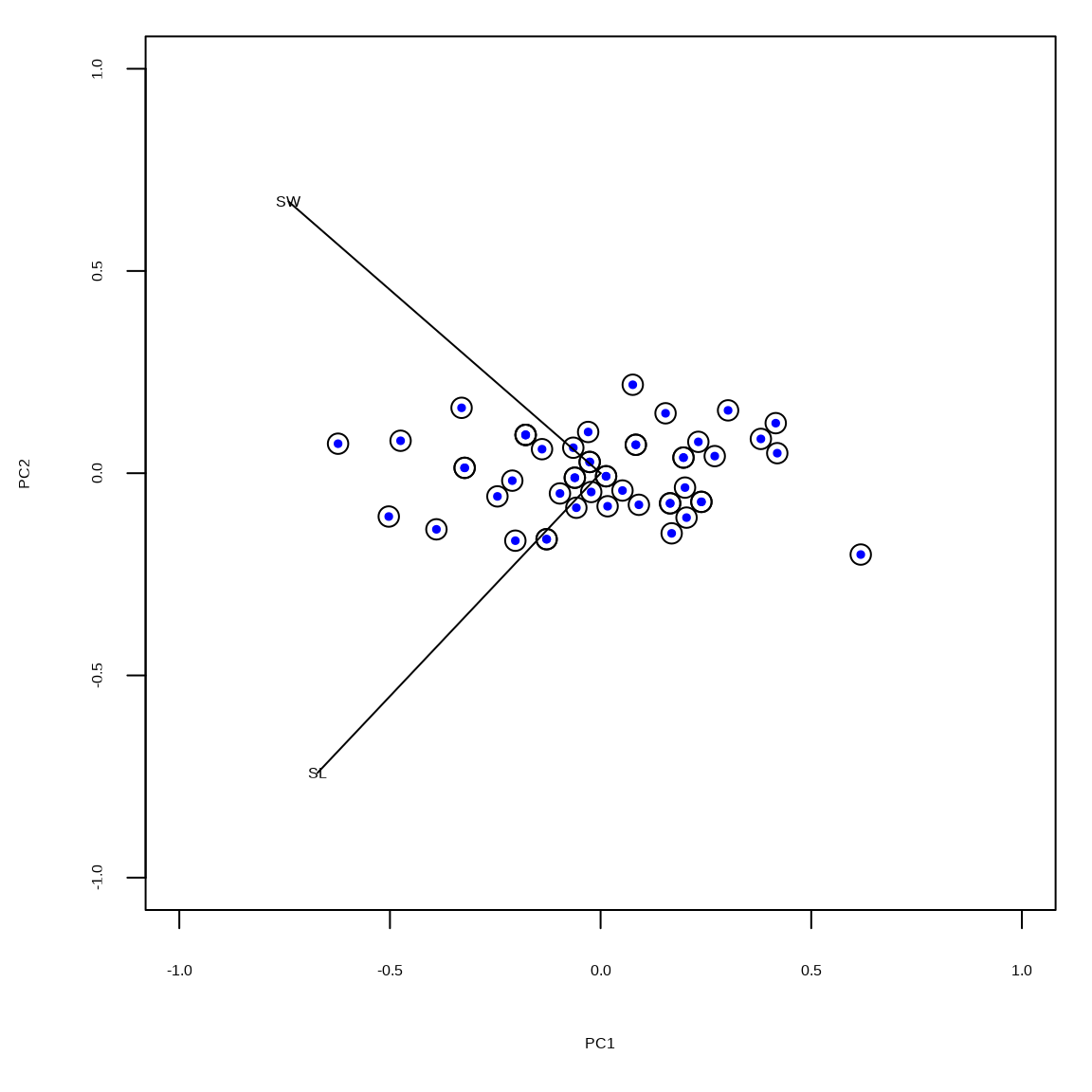
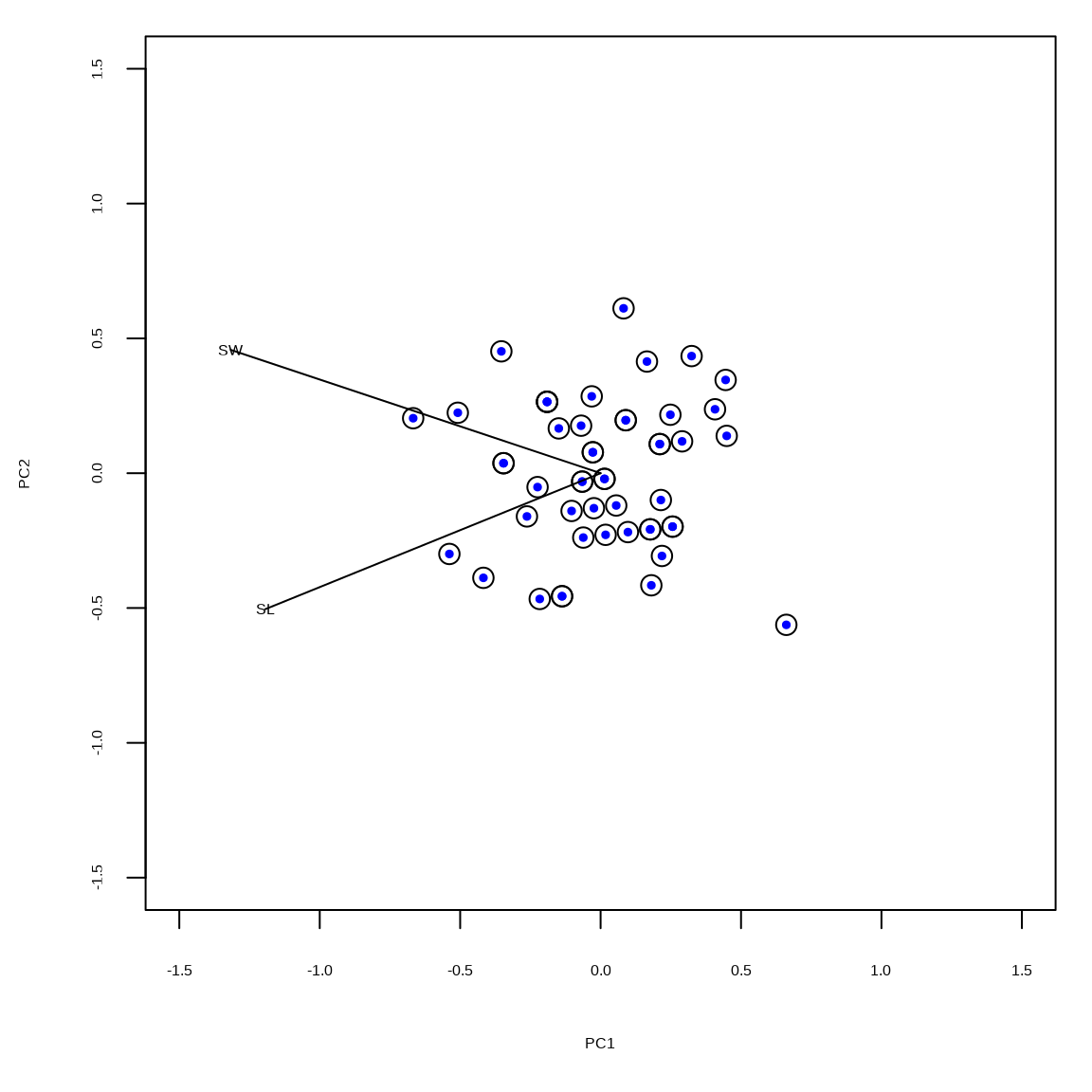
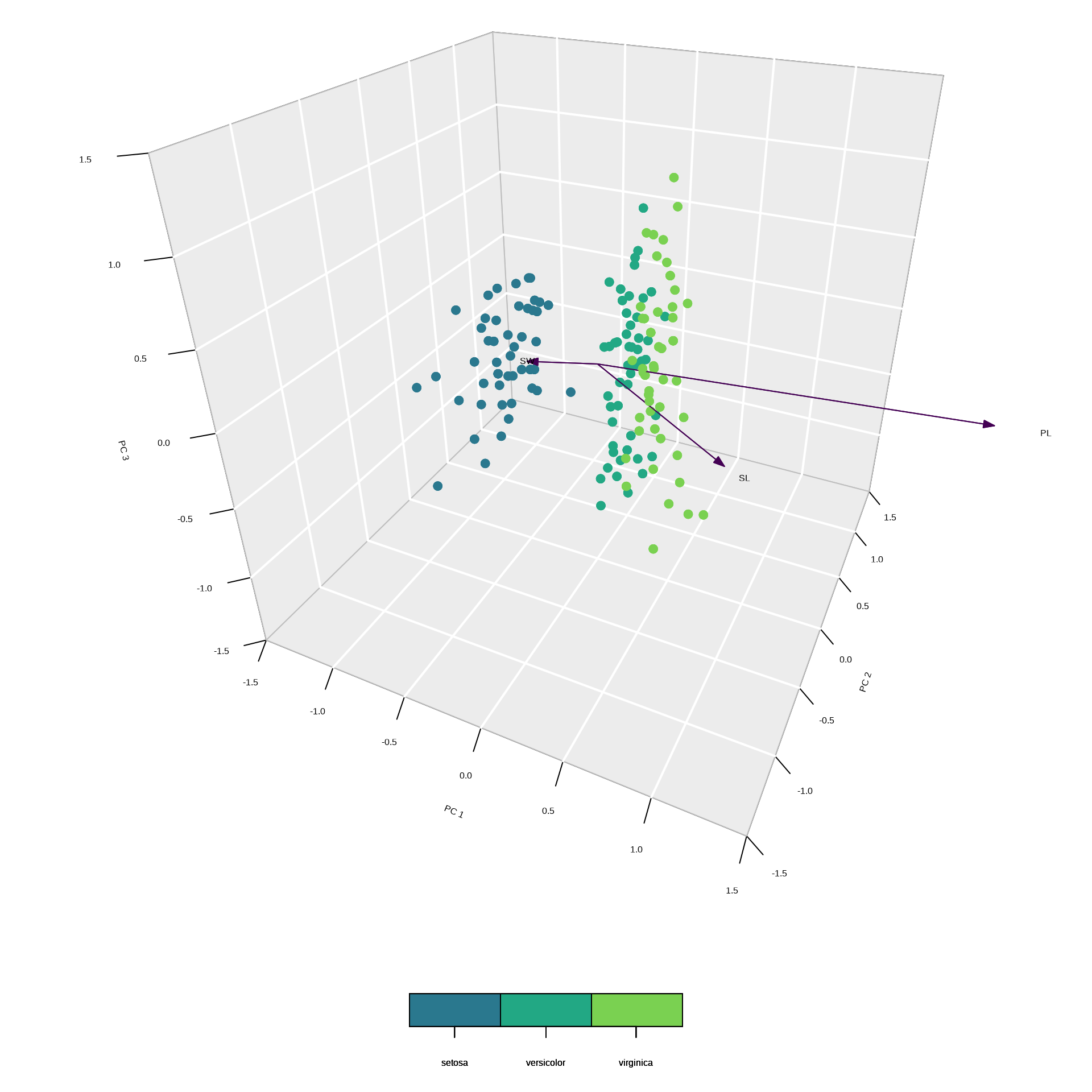
The unscaled principal components are in the matrix \(\mathbf{U}\). The black circles indicate the vegan::rda() output and the colored dots indicate the results based on the SVD.
The scaled principal components are in the matrix \(\mathbf{U}_1\). The black circles indicate the vegan::rda() output and the colored dots indicate the results based on the SVD. Distances between dots indicate approximate euclidean distances \((d = \sqrt{x^2+y^2})\)1.
The scaled principal components are in the matrix \(\mathbf{U}_2\). The black circles indicate the vegan::rda() output and the colored dots indicate the results based on the SVD. Angles between vectors (radians) indicate correlation.
Call:
rda(X = Yc)
Partitioning of variance:
Inertia Proportion
Total 3.992 1
Unconstrained 3.992 1
Eigenvalues, and their contribution to the variance
Importance of components:
PC1 PC2 PC3
Eigenvalue 3.6911 0.24138 0.05945
Proportion Explained 0.9246 0.06047 0.01489
Cumulative Proportion 0.9246 0.98511 1.00000
Scaling 2 for species and site scores
* Species are scaled proportional to eigenvalues
* Sites are unscaled: weighted dispersion equal on all dimensions
* General scaling constant of scores:
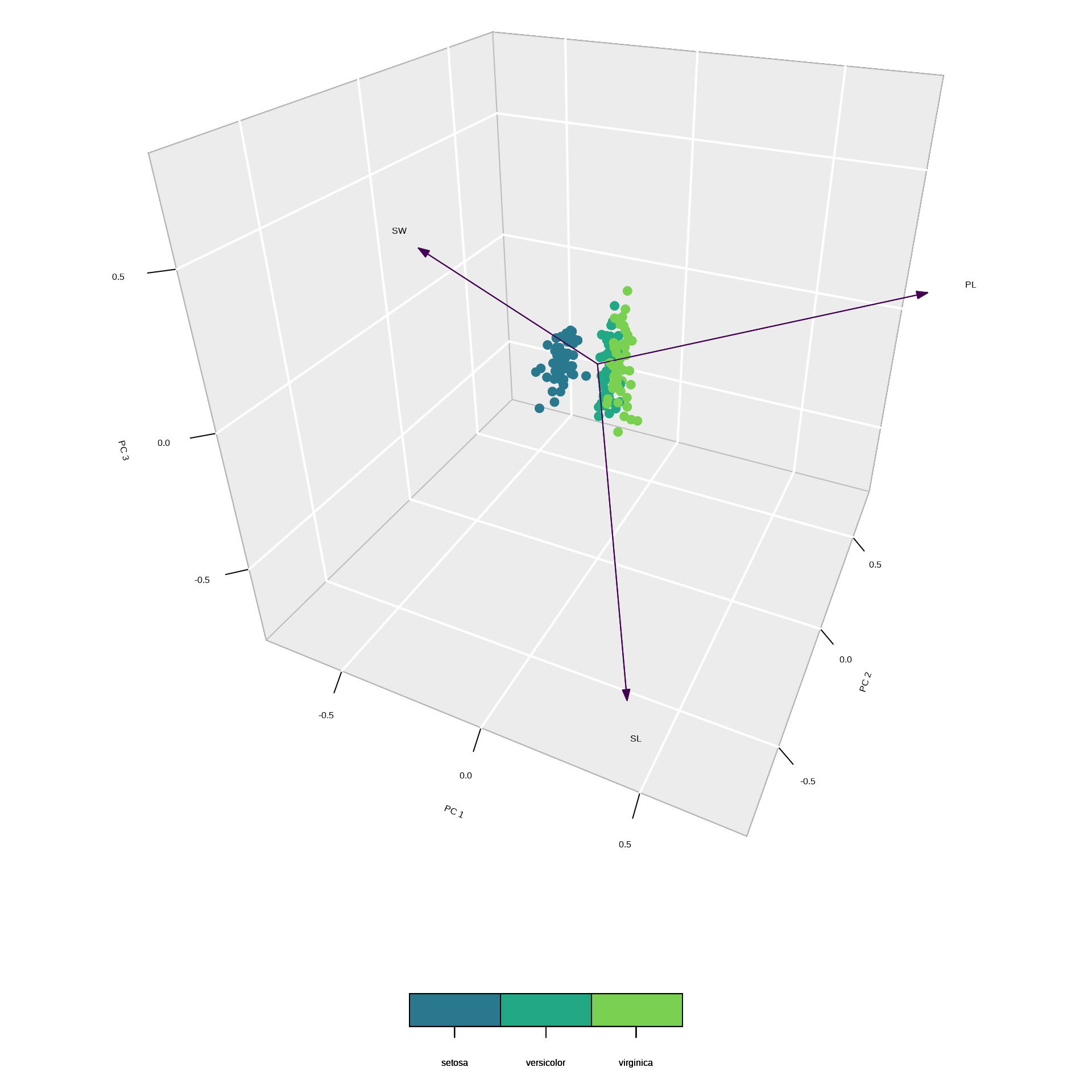
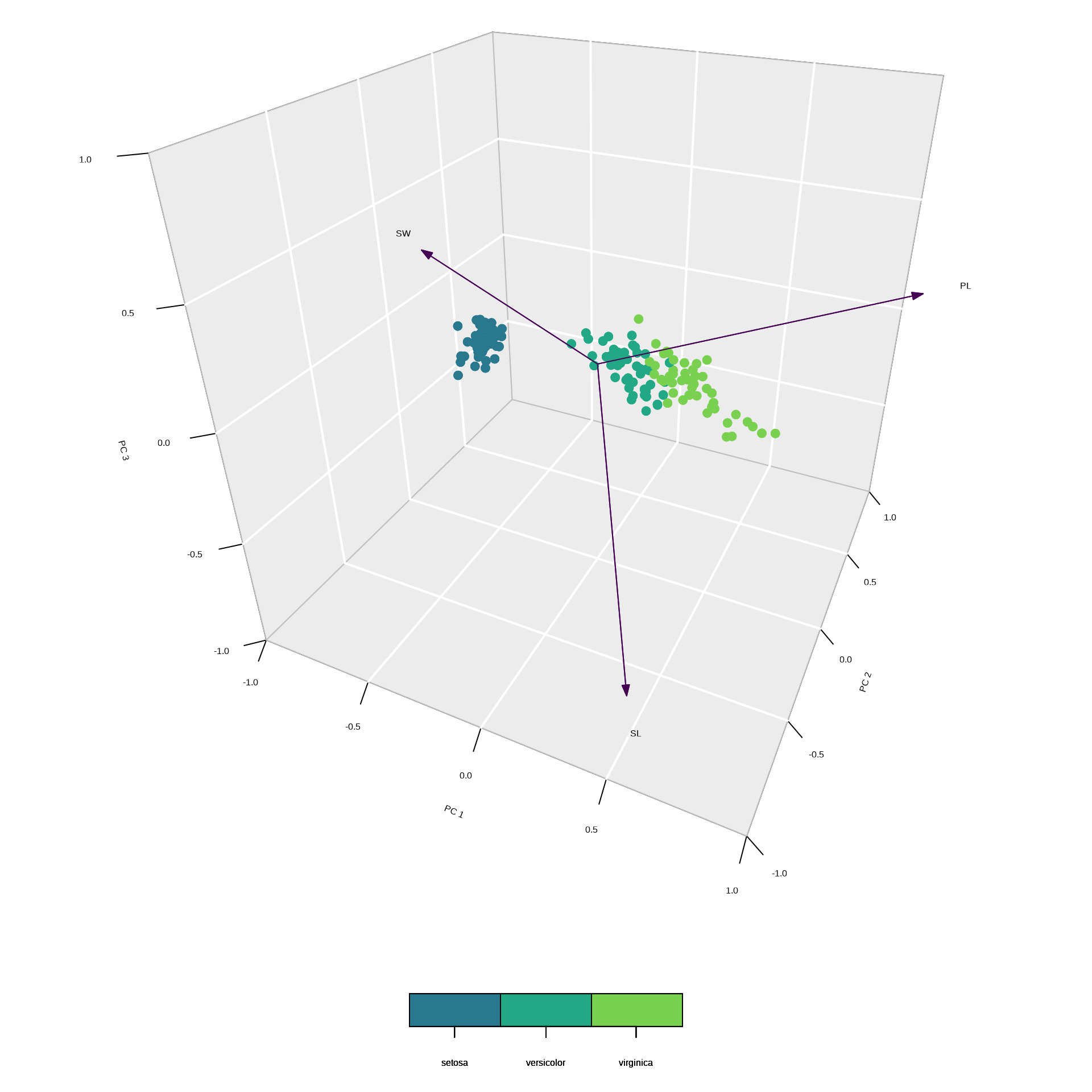
PC1 explains 92.46 % of the inertia, therefore most of the variation occurs along the PC1 axis.
Example 4: correlations among vectors
The correlation between two vectors is determined as
\[
\cos\theta = \frac{-0.26}{2.05 \times1.08} = -0.12
\] The correlation between the two vectors is -0.12. The angle between the two vectors is \(\cos^{-1}(\text{-0.1176}) =\) 1.6886 radians, or 96.7519\({}^\circ\).
The SL and PL vectors are positively correlated with PC1 (0.9045 and 0.9045, respectively). Whereas the SW vector is negatively correlated with PC2 (-0.3793).
Hotelling, H. 1933. “Analysis of a Complex of Statistical Variables into Principal Components.”Journal of Educational Psychology 24 (6): 417–41. https://doi.org/10.1037/h0071325.
Jolliffe, Ian T., and Jorge Cadima. 2016. “Principal Component Analysis: A Review and Recent Developments.”Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 374 (2065): 20150202. https://doi.org/10.1098/rsta.2015.0202.
Pearson, Karl. 1901. “LIII. On Lines and Planes of Closest Fit to Systems of Points in Space.”The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science 2 (11): 559–72. https://doi.org/10.1080/14786440109462720.