1 データの読み込み
1.2 データの確認
データは環境省の「瀬戸内海における藻場・干潟分布状況調査(概要)」からまとめました。
もとのファイルは環境省平成30年9月スライドデッキ からダウンロードできます。
XLSXファイルは readxl パッケージの read_xlsx() 関数で読み込みます。
では、XLSXファイルに存在するシートの確認をしましょう2。
rootdatafolder = rprojroot::find_rstudio_root_file("Data/")
filename = '瀬戸内海藻場データ.xlsx'
path = str_c(rootdatafolder, filename)
excel_sheets(path) # シート名を確認する
#> [1] "FY1990" "FY2018"excel_sheets() を実行したら、ファイルから 2つのシート名が返ってきました。
読み込む前に、それぞれのシートの構造を確認しましょう (Fig. 1.1 and 1.2)。
確認はスプレッドシートソフト(MS Office、 Google Sheets、 Open Office、 Apple Numbers、 など)で行います。
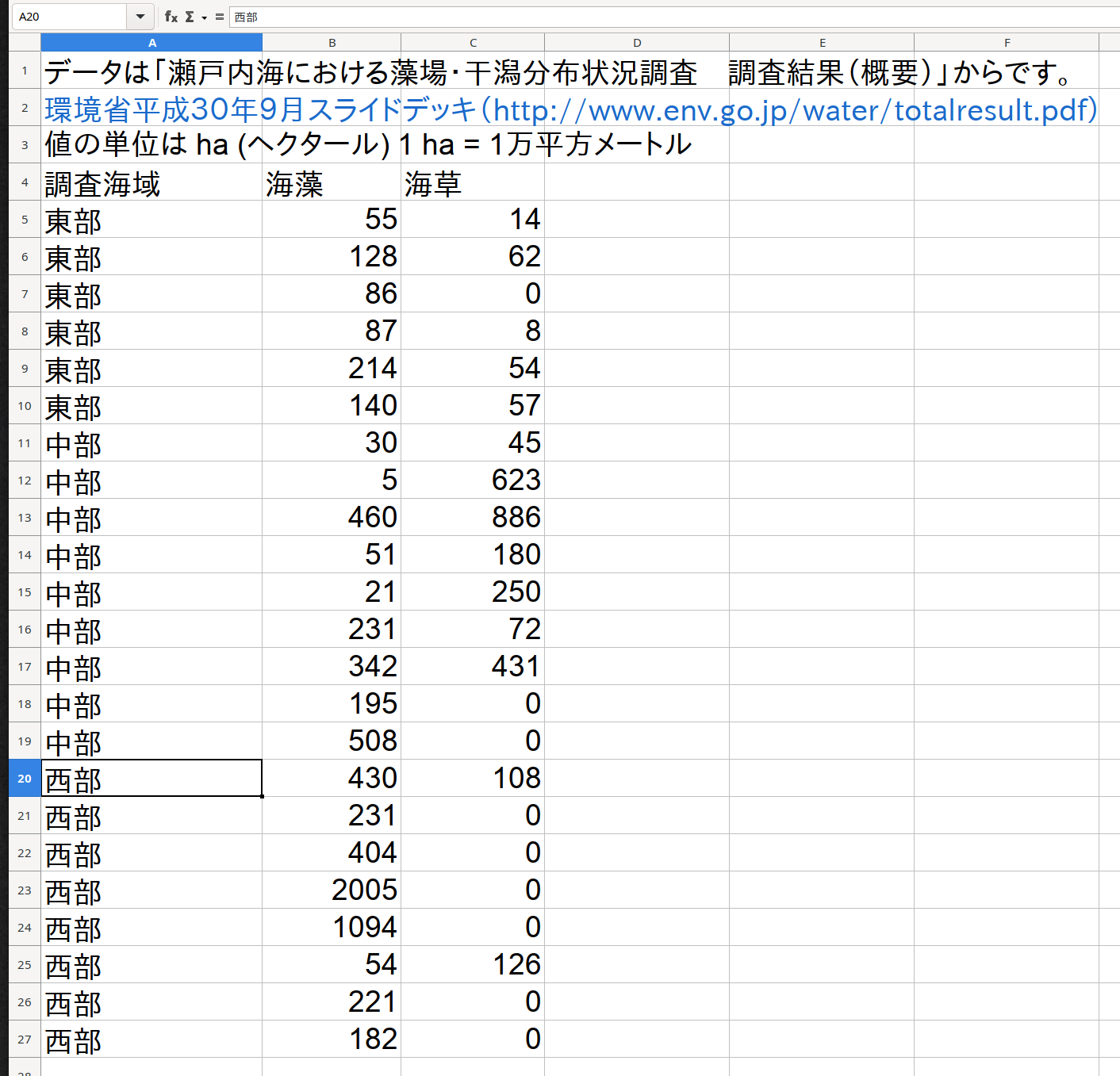
Figure 1.1: 瀬戸内海藻場データ.xlsx の FY1990 シートに入力されているデータは縦長の形式です。
FY1990 のデータの構造は縦長なので、読み込みは比較的に楽です。 それぞれの変数は一つの列3に入力されているから、読み込みが簡単です。
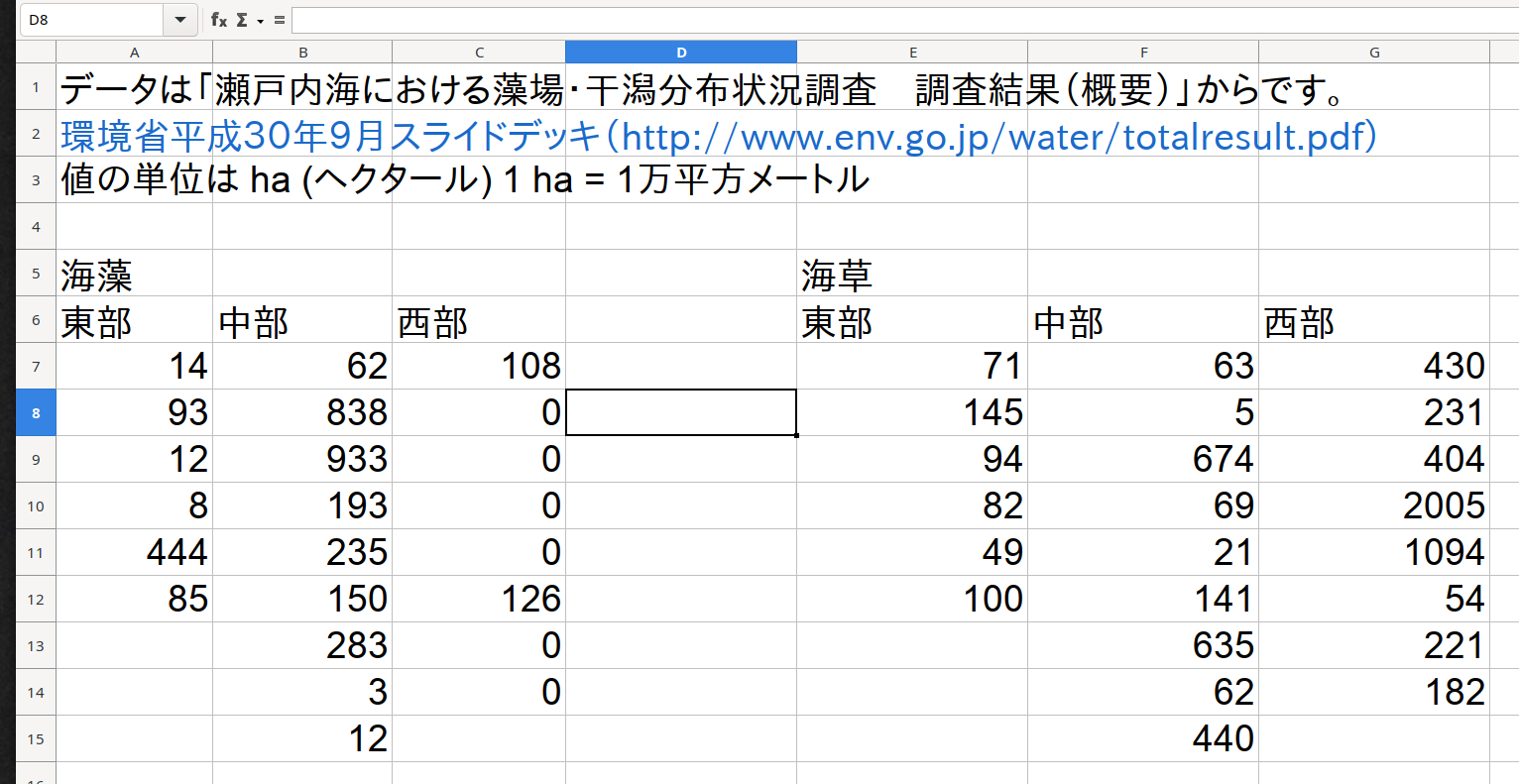
Figure 1.2: 瀬戸内海藻場データ.xlsx の FY2018 シートに入力されているデータは横長の形式です。
FY2018 のデータの構造は横長です。 データは海藻と海草にわけられ、それぞれの変数じゃなくて、それぞれの場所の値を列に入力されています。 この用なデータの読み込みは手間がかかります4。
1.3 データを読み込む
では、FY1990 シートのデータを読み込みます。 ここでシートから読み込むセルの範囲を指定します。
RNG = "A4:C27" # セルの範囲
SHEET = "FY1990" # シート名
d19 = read_xlsx(path, sheet = SHEET, range = RNG)データは tibble として読み込まれました。
データに大きな問題がなければ、各列の型・タイプ (type)5 は自動的に設定されます。
-
調査海域の列は<chr>: character, 文字列 -
海藻の列は<dbl>: double, ダブル・数値・実数 -
海草の列は<dbl>: double, ダブル・数値・実数
変数名が日本語の場合、コードが書きづらくなったり、バグの原因になります。
最初から英語表記にするのが合理的ですが、R環境内で名前を変換することは難しくないです。
とりあえず d19 の内容をみましょう。
d19 # FY1990 データの内容
#> # A tibble: 23 × 3
#> 調査海域 海藻 海草
#> <chr> <dbl> <dbl>
#> 1 東部 55 14
#> 2 東部 128 62
#> 3 東部 86 0
#> 4 東部 87 8
#> 5 東部 214 54
#> 6 東部 140 57
#> 7 中部 30 45
#> 8 中部 5 623
#> 9 中部 460 886
#> 10 中部 51 180
#> # … with 13 more rowsFY2018 シートの読み込みは、海藻と海草ごとにする必要があります。 読み込んだ後に、データを縦長に変換し、2 つの tibble を縦に結合します。
RNG = "A6:C15" # 海藻データのセル範囲
SHEET = "FY2018" # シート名
seaweed = read_xlsx(path, sheet = SHEET, range = RNG)
RNG = "E6:G15" # 海草データのセル範囲
seagrass = read_xlsx(path, sheet = SHEET, range = RNG)最初のセル範囲を読み込んで ファイルのコンテンツを seaweed に書き込んだら、RNG を次のセル範囲に書き換えます。
データは同じシートにあるので、SHEET を変更したり、新たに定義する必要はありません。
seaweed の内容は次のとおりです。
seaweed
#> # A tibble: 9 × 3
#> 東部 中部 西部
#> <dbl> <dbl> <dbl>
#> 1 14 62 108
#> 2 93 838 0
#> 3 12 933 0
#> 4 8 193 0
#> 5 444 235 0
#> 6 85 150 126
#> 7 NA 283 0
#> 8 NA 3 0
#> 9 NA 12 NAseagrass の内容は次のとおりです。
seagrass
#> # A tibble: 9 × 3
#> 東部 中部 西部
#> <dbl> <dbl> <dbl>
#> 1 71 63 430
#> 2 145 5 231
#> 3 94 674 404
#> 4 82 69 2005
#> 5 49 21 1094
#> 6 100 141 54
#> 7 NA 635 221
#> 8 NA 62 182
#> 9 NA 440 NANA は Not Available の諸略です。
Rの場合、存在しないデータ (欠損値) は NA になります。