── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
✔ ggplot2 3.4.0 ✔ purrr 1.0.1
✔ tibble 3.1.8 ✔ dplyr 1.1.0
✔ tidyr 1.3.0 ✔ stringr 1.5.0
✔ readr 2.1.3 ✔ forcats 1.0.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
tidyverse
Hadley Wickhamが開発した、タイディバースはRのプログラマーの中で最も使われているデータ分析パッケージです。 データの読み込み、抽出、加工、可視化を助けてくれる関数の解析システムです。 tidyverse の基礎となるアイディアは tidy な解析コードを開発することです。 つまり、だれでも読めるすぐに実行できるコードのことですね。
tidyversetidyverse はメタパッケージなので、library(tidyverse) を実行すると次の 8 つのパッケージが読み込まれます。
dplyr:データの変形・加工
forcats:factor() 因子が使いやすくなります
ggplot2:データの可視化・作図
purrr :関数型プログラミング
readr :CSV、TSVデータの読み込み
stringr :文字列の操作が楽になる
tibble :データフレームの操作が楽になる
tidyr :データをタイディ (tidy) にして操作しやすくなる
tidyverse の概念をもっと知りたい方は tidyverse のマニフェスト を読みましょう。
Data I/O
データ解析をするためには, データを
ベースRの関数または外部パッケージの関数を使えば, 様々なデータファイルを簡単に読み込めます。
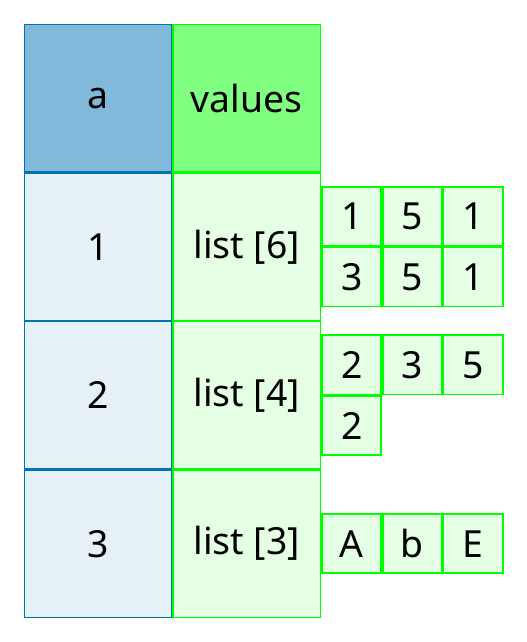
tibble には list 列を入れられるちょっと高度の方法ですが, list を変数の要素として記録できます。
= list (1 ,5 ,1 ,3 ,5 ,1 )= list (2 ,3 ,5 ,2 )= list ("A" ,"b" ,"E" )tibble (a = 1 : 3 , values = list (a1, a2, a3))
# A tibble: 3 × 2
a values
<int> <list>
1 1 <list [6]>
2 2 <list [4]>
3 3 <list [3]>
values 列は list の list ですね。
列名・変数名について
data.frame() は無効な変数名を自動的に変更します。
data.frame (` 1 name ` = 1 ) |> names ()
tibble() はそのままにしてくれます。
tibble (` 1 name ` = 1 ) |> names ()
data.frame()の場合有効な変数名: 文字または、ドット(.)と文字から始まる文字列。変数名に使用できるものは文字、数字、ドットとアンダースコア (_) だけです。 * 無効な変数名の例: 2021FY, 2021 FY, 2020-FY, FY-2021 は自動的に X2021FY, X2021.FY, X2020.FY, FY.2021 に変更されます。
tibble()の場合` ` (バクチック)に囲んでください。
ところが! どうしても data.frame() に無効な変数名を使いたいのであれば、check.names = F を渡してください。
data.frame (` 1 name ` = 1 , check.names = FALSE ) |> names ()
引数を連続的に使える
tibble()はこのように, 計算処理をしながらデータフレームを構築できます。
tibble (x = 1 : 4 , ` x^2 ` = x^ 2 , ` sqrt(x) ` = sqrt (x))
# A tibble: 4 × 3
x `x^2` `sqrt(x)`
<int> <dbl> <dbl>
1 1 1 1
2 2 4 1.41
3 3 9 1.73
4 4 16 2
ベクトルをリサイクルしない
二つのベクトルの長さが異なるときに, データフレームを作ると, 小さいほうのベクトルは先頭から繰り返して使われます。ただし長いベクトルの要素数は短いベクトルの要素数で除算できる必要があります。
= 1 : 4 = 1 : 8 data.frame (x, y)
x y
1 1 1
2 2 2
3 3 3
4 4 4
5 1 5
6 2 6
7 3 7
8 4 8
ところが, この機能はデータ解析時にバグの原因になります。tibble()はベクトルのリサイクルはできません。
= 1 : 4 = 1 : 8 tibble (x, y)
Error:
! Tibble columns must have compatible sizes.
• Size 4: Existing data.
• Size 8: Column at position 2.
ℹ Only values of size one are recycled.
I/O 関係の関数
読み込み関数
read_delim():一般性の高い関数, 区切りの指定が必要read_csv():コンマ区切りフィアルの読み込み(csv ファイル)read_table():ホワイトスペース区切りファイルの読み込み(タブ・スペース区切りファイル)read_rds():R オブジェクトの読み込み
書き出し関数
write_delim():一般性の高い関数, 区切りの指定が必要write_csv():コンマ区切りフィアルの書き出しwrite_excel_csv():Excel 用にコンマ区切りフィアルを書き出すwrite_table():ホワイトスペース区切りファイルの書き出し(タブ・スペース区切りファイル)write_rds():R オブジェクトの書き出しggsave(): ggplot2 でつくった図を書き出し
read_csv() の重要な引数
file:パスとファイル名col_names = TRUE:TRUEのとき, 1行目は列名として使う, FALSE のときは列名を自動的に作成する, 文字列ベクトルを渡せば読み込み中に列名を付けられますcol_types = NULL:列のデータ型を指定できるが NULL のときは関数に任せるcomment = "":コメント記号を指定し, コメント記号後の文字を無視するskip = 0 先頭から無視する行数locale:ロケール(地域の設定)n_max = Inf:読み込む行数、デフォルトは全ての行数
read_csv()の使い方read_csv()
= read_csv ("Assignment_06_Dataset01.csv" )
Rows: 37 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): host
dbl (1): scutum.width
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# A tibble: 37 × 2
host scutum.width
<chr> <dbl>
1 Rabbit1 380
2 Rabbit1 376
3 Rabbit1 360
4 Rabbit1 368
5 Rabbit1 372
6 Rabbit1 366
7 Rabbit1 374
8 Rabbit1 382
9 Rabbit2 350
10 Rabbit2 356
# … with 27 more rows
readxl パッケージ
readxl は Microsoft Excelファイルの読み込みに使えるパッケージです。
ファイルの読み込みには read_excel() を使いますが、研究室では read_xlsx() もよく使います。 read_excel() は read_xlsx() のラッパーです。 使い方は全くおなじです。
重要: エクセルでデータの管理をした場合エクセルのオートコレクト機能によってデータがかってに変換されるので気をつけましょう。遺伝子の名前のオートコレクトによく問題が発生すると報告されています。とくに Excel と Google Sheets のオートコレクトはアグレッシブです。Abeysooriya et al. 2021. PLOS Computational Biology 。
read_excel() の主な引数
path:パスとファイル名sheet = NULL:読み込むシート名またはシートインデックスrange = NULL:読み込む範囲, 例えば “B3:D8” または, “Data!B3:D8”col_names = TRUE:1行目を列名として使う論理値col_types = NULL:読み込む列のデータ型を指定できます (デフォルトは guess)na = "":欠損値の定義, 空セルは欠損値とされますskip = 0:無視する行数n_max = Inf:読み込む最大行数
read_excel() の使用例(1)最初のシート (sheet = 1) の先頭から1行無視して (skip = 1) データを読み込む。
= "Table 2.xlsx" = read_excel (filename, sheet = 1 , skip = 1 )
New names:
• `WT (˚C)` -> `WT (˚C)...2`
• `S.D.**` -> `S.D.**...3`
• `` -> `...4`
• `WT (˚C)` -> `WT (˚C)...5`
• `S.D.**` -> `S.D.**...6`
# A tibble: 12 × 6
Month `WT (˚C)...2` `S.D.**...3` ...4 `WT (˚C)...5` `S.D.**...6`
<chr> <dbl> <dbl> <lgl> <dbl> <dbl>
1 Jan. 21.1 0.446 NA 16.5 0.428
2 Feb. 21.3 0.441 NA 16.3 0.483
3 Mar. 21.5 0.470 NA 16.5 0.579
4 Apr. 21.8 0.554 NA 18.3 1.27
5 May 23.4 0.726 NA 21.1 1.08
6 Jun. 25.5 1.20 NA 22.9 1.02
7 Jul. 28.6 0.491 NA 26.6 1.15
8 Aug. 28.8 0.546 NA 28.5 0.470
9 Sep. 28.5 0.375 NA 27.7 0.794
10 Oct. 26.6 0.893 NA 24.4 1.05
11 Nov. 24.7 0.516 NA 21.6 0.928
12 Dec. 22.8 0.720 NA 19.1 0.893
read_excel() の使用例(2)先程のように読み込むと、不都合な変数名に変換されました。次は、変数名も指定して読み込みます。
= "Table 2.xlsx" = c ("month" , "temperature1" , "sd1" , "empty" ,"temperature2" , "sd2" )= read_excel (filename, sheet = 1 , skip = 2 , col_name = col_names)|> print (n = 4 )
# A tibble: 12 × 6
month temperature1 sd1 empty temperature2 sd2
<chr> <dbl> <dbl> <lgl> <dbl> <dbl>
1 Jan. 21.1 0.446 NA 16.5 0.428
2 Feb. 21.3 0.441 NA 16.3 0.483
3 Mar. 21.5 0.470 NA 16.5 0.579
4 Apr. 21.8 0.554 NA 18.3 1.27
# … with 8 more rows
シートの2行目には変数名が記録されているので、skip = 2 を渡しました。
データの出力
CSVファイルの出力
= "table2_output.csv" |> write_csv (file = fname) # 文字コードは UTF-8 です。
エクセルにCSVファイルを読み込んで文字化けした場合、write_excel_csv()を試してみてください。
|> write_excel_csv (file = fname)
RDSファイルの出力
Rのオブジェクトをバイナリファイルとして保存したい場合は write_rds() を使います。
= "table2_output.rds" |> write_rds (file = fname)